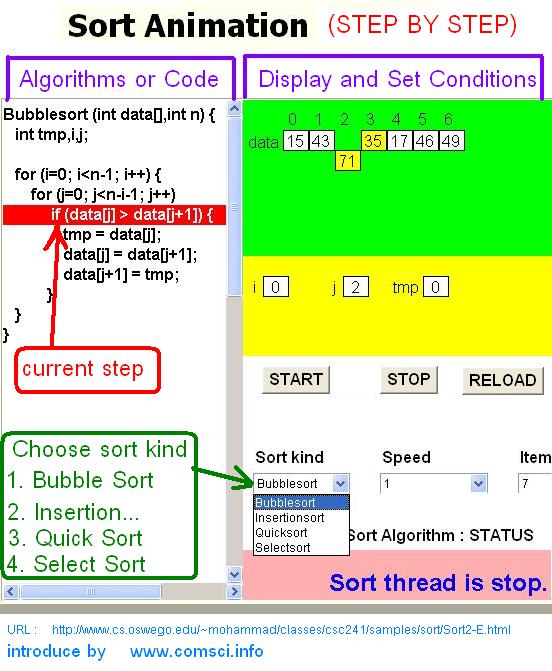
In computer science, a data structure is a particular way of storing and organizing data in a computer so that it can be used efficiently. Different kinds of data structures are suited to different kinds of applications, and some are highly specialized to certain tasks. For example, B-trees are particularly well-suited for implementation of databases, while compiler implementations usually use hash tables to look up identifiers. Data structures are used in almost every program or software system. Specific data structures are essential ingredients of many efficient algorithms, and make possible the management of huge amounts of data, such as large databases and internet indexing services. Some formal design methods and programming languages emphasize data structures, rather than algorithms, as the key organizing factor in software design.
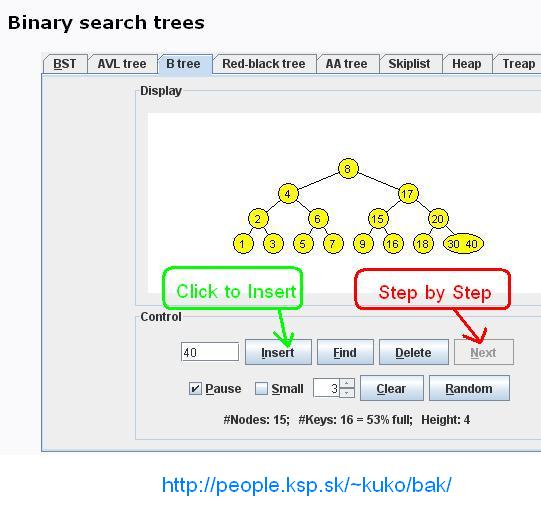
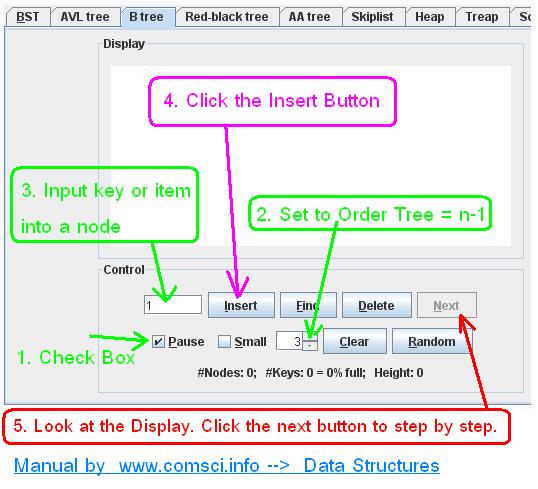
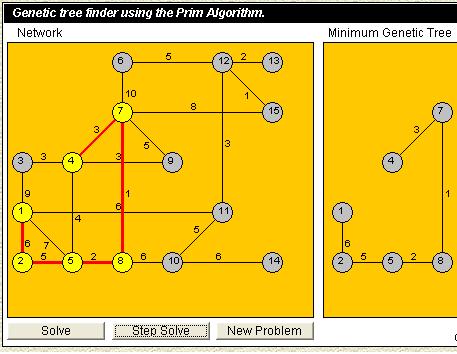
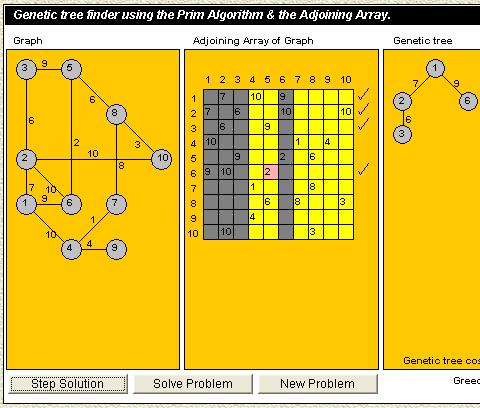
- This applet animates the functioning of several dictionary data structures. It can be used as a teaching aid or for self-study. By watching the visualization the user should more easily grasp the ideas behind the data structures.
URL : http://people.ksp.sk/~kuko/bak
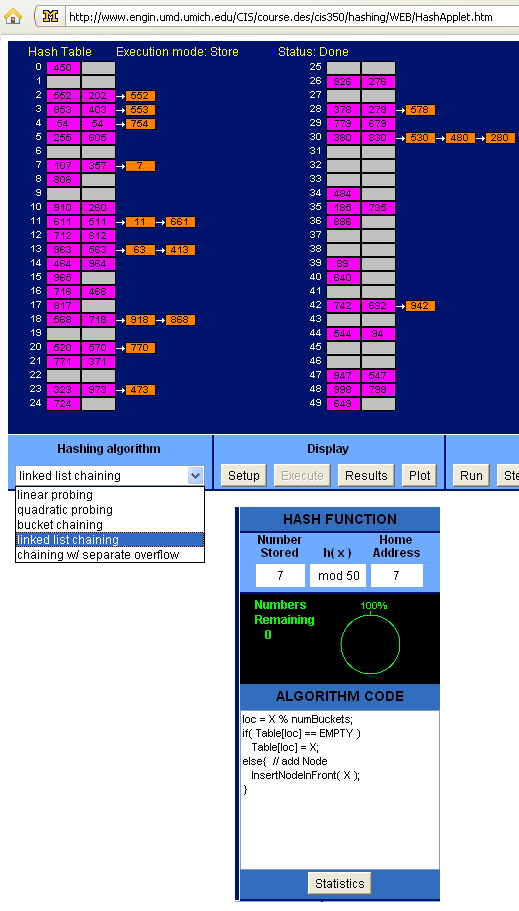
The Hashing Animation Tool is implemented as a Java applet. In order to view the applet a Java enabled web browser that supports Java 1.1, such as Internet Explorer 4+ or Netscape Navigator 4+, is required. In addition, due to the dimensions of the applet a monitor resolution of at least 1027 x 768 is recommended. Finally, the file size for the applet is fairly large. Users with dial-up connections may need to wait a minute or so for the applet to finish loading.
URL : http://www.engin.umd.umich.edu/CIS/course.des/cis350/hashing/WEB/HashApplet.htm
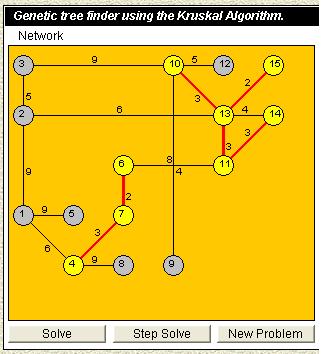
The Kruskal Algorithm starts with a forest which consists of n trees.Each and everyone tree,consists only by one node and nothing else.In every step of the algorithm,two different trees of this forest are connected to a bigger tree.Therefore ,we keep having less and bigger trees in our forest until we end up in a tree which is the minimum genetic tree (m.g.t.) .In every step we choose the side with the least cost,which means that we are still under greedy policy.If the chosen side connects nodes which belong in the same tree the side is rejected,and not examined again because it could produce a circle which will destroy our tree.Either this side or the next one in order of least cost will connect nodes of different trees,and this we insert connecting two small trees into a bigger one.
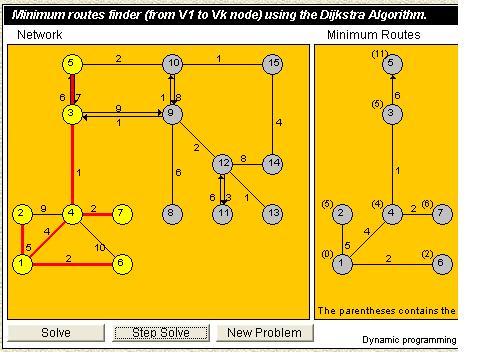
This algorithm finds the routes,by cost precedence.Let's assume that every cost is a positive number,and assume the same in the cost function c as in 5.4 paragraph.G may be a graph,a digraph,or even a combined one,which means that only some of its sides are directed.If we consider G as digraph,then every other case is fully covered as well since a no directed side can be considered a 2 directed sides of equal cost for every direction.
URL : http://students.ceid.upatras.gr/~papagel/project/kef5_7_1.htm
1.1 Data abstraction of Polynomials 1.1.1 Concept of Polynomials
Please wait to data update...
1.1.2 Pseudocode and Algorithms of Polynomials
Algorithm makeZeroPolynomial(polyterm)
maxDegree � the highest possible degree of polynomial
polyterm � pointer to the polynomial structure
i � index to current member of array
Begin
for(int i = 0; i <= maxDegree; i++)
(Set CoefficientArray[i] of polyTerm to 0)
(Set HighestPower to 0)
End
Algorithm addPolynomial(poly1, poly2, polySum)
maxDegree � the highest possible degree of polynomial
poly1,poly2 � polynomial terms to be added together
polySum � resulted polynomial
i � index to current member of array
Begin
(Call Procedure MakeZeroPolynomial(polySum))
(HighestPower of polySum = maximum between HighestPower of poly1 and HighestPower of poly2)
for(i=(HighestPower of polySum); i>=0; i--)
{
(CoefficientArray[i] of polySum) = (CoefficientArray[i] of poly1) + (CoefficientArray[i] of poly2)
}